

Introduction
EVL Data Anonymization Microservice enables fast, automated and cost-effective anonymization of data sets. It can be used for anonymization of the production data according to GDPR requirements as well as for the protection of commercially sensitive data for developers, testers and other outside contractors.
EVL Anonymization belongs to the portfolio of other Metadata-driven EVL Microservices, which provide fast and automated solution for a specific business purpose, but keep common metadata structure so other such EVL Microservices can be plugged-in easily.
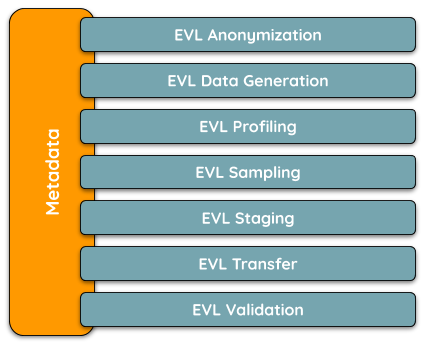
Figure 1.1: EVL Metadata-driven Microservices
All EVL Microservices are built on top of the core EVL software and retain its flexibility, robustness, high productivity, and ability to read/write various file formats and databases.
EVL
EVL originally stood for Extract–Validate–Load, but it’s now a fully featured ETL (Extract–Transform–Load) tool.
EVL is designed with the Unix philosophies of interoperability and “do one thing, and do it well” in mind.
Templates, a high level of abstraction, and the ability to dynamically create jobs, make for a powerful ETL tool.
Characteristics
- Versatile, i.e. cooperate with other components of the customer’s solution, solving only particular problem.
- High performance, written in C++.
- Lightweight, just install a rpm/deb package or unzip tgz.
- Highly efficient development due to strict command-line approach.
- Managed access to the source code (e.g.
git). - Linux only, using the best of the system.
- Graphical User Interface – EVL Manager.
Features
- Natively read/write1:
- File formats: CSV, JSON, XML, XLS, XLSX, Parquet, Avro, QVD/QVX, ASN.1
- DBMS: MariaDB/MySQL, Oracle, PostgreSQL, SQLite, ODBC, (near future: Snowflake, Redshift)
- Cloud storages: Amazon S3 and Google Storage
- Hadoop: read/write HDFS, resolve, build and run Spark jobs, Impala/Hive queries
- Partitioning, to partition data and/or parallelize processing
- Productivity boosters, to generate jobs/workflows from metadata
For the most recent information about EVL and supported formats and DBs please check https://www.evltool.com.
EVL Microservices
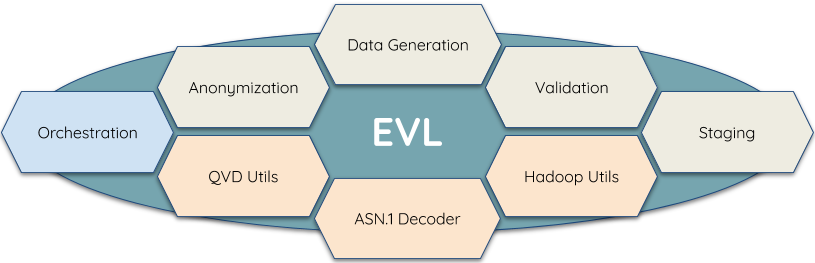
Figure 1.2: EVL Microservices Overview
Each of the Microservice solves particular problem:
- Anonymization
Anonymizing production data according to GDPR requirements and other regulations for developers, testers and outside contractors
- Data Generation
Simulating data complying with the real-life data patterns for proper testing environments, application development and implementing ETL processes
- Validation
Replacing heavy and complex testing tools in migration projects or quick quality checks of production data
- Staging
Getting data from various sources, like Oracle, Teradata, Kafka, CSV or JSON files, and providing a historized base stage
- QVD Utils
Enables reading/writing QVD files without using Qlik Sense or QlikView and also provides metadata from QVD/QVX header.
- Hadoop Utils
Reading/writing Parquet and Avro file formats, query Impala, Hive, etc.
- ASN.1 Decoder
Decoding files from ASN.1 format into JSON with the highest performance
- Orchestration
Scheduling and monitoring sequences of jobs and workflows, awaiting file delivery, etc. Viewing the workflows in a graphical user interface and starting, restarting, canceling jobs and workflows and checking their statistics and logs.
But they could supply each other, so combining them one get the whole solution.
For the most recent list of EVL Microservices and additional information please visit https://www.evltool.com.